庄伟铭
论文题目:Performance Optimization for Federated Person Re-identification via Benchmark Analysis
开源代码:https://github.com/cap-ntu/FedReID
行人重识别的训练需要收集大量的人体数据到一个中心服务器上,这些数据包含了个人敏感信息,因此会造成隐私泄露问题。联邦学习是一种保护隐私的分布式训练方法,可以应用到行人重识别上,以解决这个问题。但是在现实场景中,将联邦学习应用到行人重识别上因为数据异构性,会导致精度下降和收敛的问题。
(数据异构性:数据非独立分布 (non-IID) 和 各端数据量不同。)

这是篇来自 ACMMM20 Oral 的论文,主要通过构建一个 benchmark,并基于 benchmark 结果的深入分析,提出两个优化方法,提升现实场景下联邦学习在行人重识别上碰到的数据异构性问题。
本文主要对这篇文章的这三个方面内容做简要介绍:
1. Benchmark: 包括数据集、新的算法、场景等
2. Benchmark 的结果分析
3. 优化方法:知识蒸馏、权重重分配
Benchmark
数据集
数据集由9个最常用的 行人重识别 数据集构成,具体的信息如下:

这些数据集的数据量、ID数量、领域都不同,能够有效的模拟现实情况下的数据异构性问题。
算法
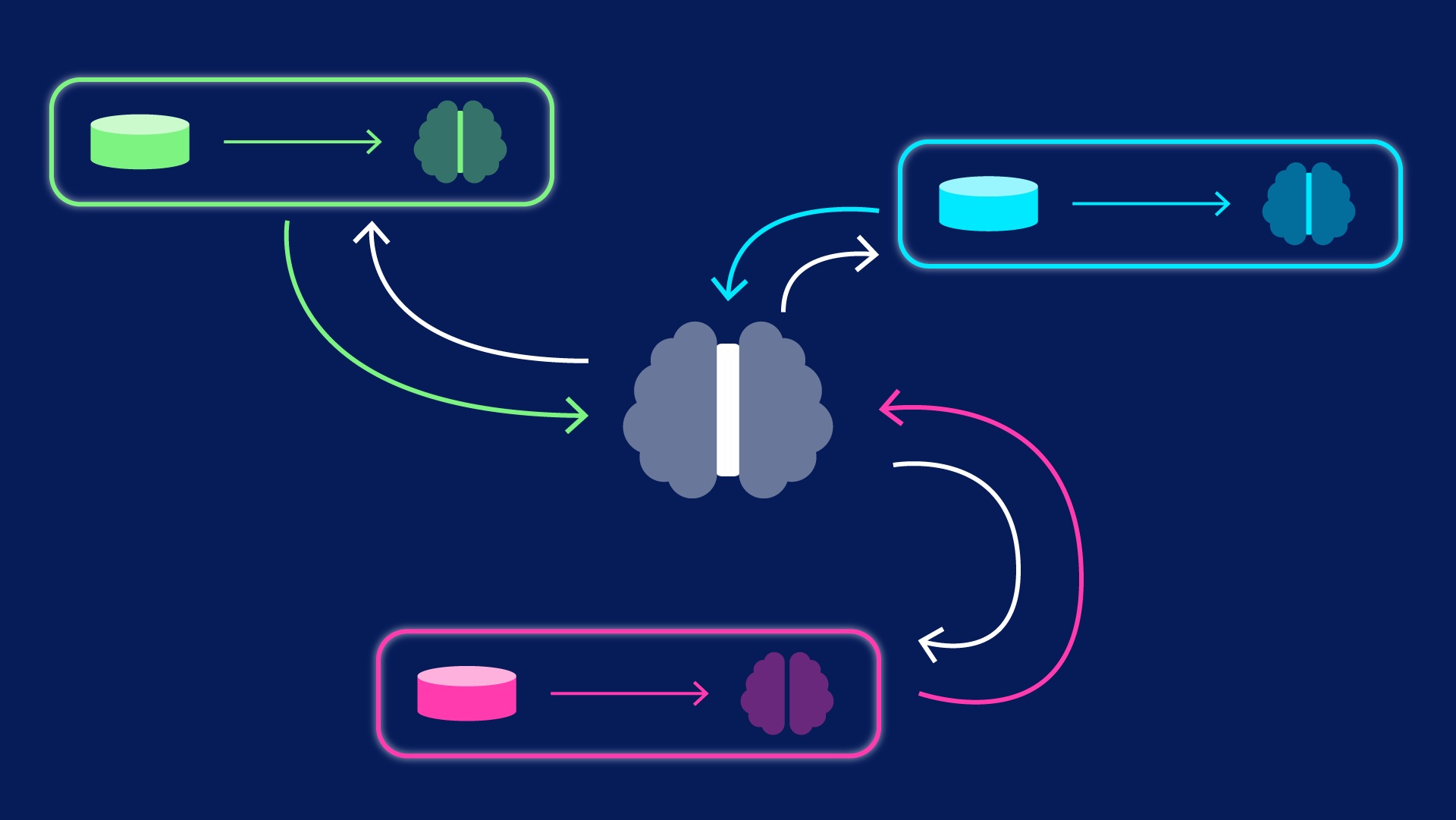
传统联邦学习算法 Federated Averaging (FedAvg) 要求端边全模型同步,但是 ReID 的分类层的维度由 ID数量决定,很可能是不同的。所以这篇论文提出了只同步部分的模型 Federated Partial Averaging (FedPav).

Benchmark 结果分析
通过 Benchmark 的实验,论文里描述了不少联邦学习和行人重识别结合的洞见。这边着重提出两点因数据异构性导致的问题。
1. 大数据集在联邦学习中的精度低于单个数据集训练的精度

- FedPav: 联邦学习总模型的精度
- FedPav Local Model: 联邦学习各边端模型模型上传前在各自边端测试的精度
- Local Training: 基准,每个数据集单独训练和测试的精度
Local Training 效果比联邦学习的效果好,说明这些大数据集没法在联邦学习中受益。需要有更好的算法来提高精度。
2. 联邦学习训练不收敛

通过这两个数据集测试曲线可以看出,因为数据异构性的影响,精度波动较大,收敛性差。
优化方法
采用知识蒸馏,提高收敛

将每个 Client 做为教师模型,Server 作为学生模型,进行知识蒸馏,以更好的把 Client 学到的知识传递到 Server 上,能够有效提高收敛(下图橙线)

提出权重重分配,提高精度
调整联邦学习模型融合时各方模型更新的权重:给训练效果越好的边端,分配更大的权重,在模型融合时产生更大的影响。

权重重分配使所有边端模型的性能都超过 Local Training,带来普遍的性能提升。

总结
针对数据隐私问题,这篇论文将联邦学习应用到行人重识别,并做了深入的研究分析。构建了一个 Benchmark,并基于实验结果带来的洞见,提出了使用知识蒸馏和权重重分配的方法来解决数据异构性带来的性能问题。
算法细节和更多实验结果,推荐阅读原论文和开源代码。