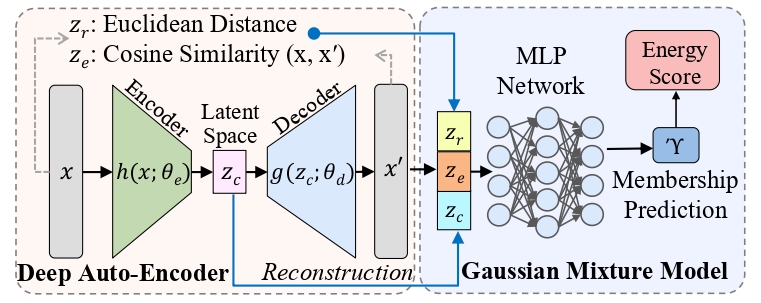
基于DCTwin的工程实践 近日,南洋理工大学CAP团队在GitHub上开源了数据中心CFD仿真工具DCTwin(https://github.com/CAP-GDCR/Dctwin-CFD )。DCTwin是一个基于OpenFOAM的自动化CFD框架,接收JSON格式的仿真配置文件(.cfdrun)与预导出的多区域STL几何文件,自动完成从blockMesh、snappyHexMesh网格生成到边界条件配置与求解的完整流程。本文基于DCTwin的开发实践,分享我们在边界条件设置、自动网格加密和收敛判据方面遇到的具体问题与解决方案。 1. 引言 数据中心的热管理问题正在变得越来越工程化和系统化。机柜功率密度提升、冷热通道组织、架空地板送风、空调回风路径和局部热点之间相互耦合,使得单靠经验规则很难判断一个布局是否可靠。CFD仿真能够在设计阶段给出温度、速度和压力场的空间分布,但真正落地时,工程师还要面对几何建模、网格划分、边界条件、求解控制和后处理等一整套工具链问题。在这个背景下我们开发了DCTwin数据中心热仿真数字孪生工具。以OpenFOAM为底层CFD求解器,而是面向数据中心场景,把几何建模、仿真配置、STL导出、OpenFOAM网格/求解以及浏览器端后处理串成一条相对完整的自动化流程。一方面降低OpenFOAM在数据中心CFD场景中的使用门槛,另一方面也是为了让仿真过程更容易被脚本、批量工况和未来的AI Agent工作流调用。 在这个过程中,我们逐渐发现,数据中心CFD热仿真的核心挑战并不只是“把模型建完跑起来”。服务器和空调(CRAC/ACU)等核心设备通常不解析其内部流场,而是作为”黑箱”进行建模:服务器被简化为一个穿流通道——冷空气从前面板进入,经过芯片散热后从背板排出热空气;空调则被简化为一个冷源——回风口吸入热空气,送风口排出冷空气。这种黑箱建模方式是数据中心CFD中的常见做法[1],但边界条件、网格分辨率和收敛判据的细节会显著影响结果的可信度。 因此,本文的目的是分享我们在开发过程中遇到的一些具体问题和对应解决办法。其中,边界条件看似只是输入参数的选择问题,实际上牵涉到求解器的收敛特性;网格加密看似只是精度设置,实际上会影响薄壁结构和零厚度baffle能否被稳定解析;残差收敛看似给出了停止标准,实际上不一定代表温度场已经达到物理稳态。下面我们围绕这几类问题展开,希望这些经验对从事数据中心CFD仿真的工程师和研究者有所帮助。图1展示了本文讨论对象对应的三维机房几何模型。 图1:DCTwin三维建模界面,展示数据中心机房的几何模型构建 2. CRAC热边界条件 在我们的调试经验里,空调边界常常比预期更容易被低估。几何模型看起来正确、风量和功率也填得完整,但只要送风温度的边界条件与求解器迭代方式不匹配,温度场就可能表现出持续漂移或难以稳定的问题。我们在DCTwin调试中遇到的一个典型教训,正是CRAC热边界条件并不是“把公式写进去”那么简单,而是要同时考虑物理含义和数值收敛性。 2.1 四种CRAC边界条件方法 CoolSim白皮书WP105[2]系统总结了数据中心CFD中CRAC的四种热边界条件设置方法。第一种是固定送风温度(Supply Temperature),直接将送风口温度指定为常数值,例如20°C。这是最简单也最常用的方式,适用于送风温度由空调控制器调节并在设定值附近波动的场景。具体控制精度取决于设备、控制策略和运行工况;在稳态CFD中,将送风温度建模为常数通常是一个可控的工程近似。 第二种是温降法(Temperature Drop),指定回风与送风的温差 ΔT = T_return – T_supply,送风温度随回风温度动态变化。这种方式隐含了一个假设:空调的制冷能力足以维持恒定的温降,无论热负荷如何变化。在设计工况下这一假设成立,但在过载或部分负荷工况下可能偏离实际。 第三种是制冷量法(Cooling Capacity),指定空调的制冷量Q,根据能量守恒公式 Q = ṁ·cp·(T_return – T_supply) 反算送风温度。这种方法能够表达空调制冷能力的上限——当热负荷超过额定制冷量时,Q被截断为Q_max,送风温度相应升高,通常比固定温降更接近过载工况下的物理行为。第四种是性能曲线法(Performance Data),使用空调厂商提供的多维性能曲线,制冷量随回风温度、湿度等参数变化,能更贴近具体设备特性,但实现和数据准备也最复杂。 在实际应用中,固定送风温度是稳态仿真中常见的选择[1]。这不仅是因为实现简单,也因为在稳态SIMPLE求解框架下,一个明确的送风温度Dirichlet边界通常更有利于获得稳定的温度场。下面我们将解释为什么带反馈的制冷量表达式在稳态求解中可能遇到麻烦。 2.2 Expression BC在稳态SIMPLE中的陷阱 一个自然的想法是在稳态仿真中使用制冷量法,即通过OpenFOAM的expression BC让送风温度根据回风温度动态计算: T_supply = max(T_return – Q_actual / (ṁ · cp), T_min) 其中 Q_actual = min(Q_needed, Q_max),Q_needed = […]
Read More